3 Fundamentos teóricos
En este capitulo introduciremos primero fundamentos teóricos que nos ayuden a comprender como se construyen los modelos matemáticos. Para luego ver como estos son analizados. Empezaremos estudiando un modelo en una dimensión para luego ver un ejemplo en más dimensiones. En las siguientes secciones haremos algunos usos impreciso de la nomenclatura matemática con el propósito hacer más simple y didáctico el desarrollo y análisis de los modelos.
3.1 Mi primer modelo matemático
Empezaremos por construir un modelo de crecimiento de una población. Diremos entonces que la tasa de cambio en el tamaño de la población estará gobernada por la tasas de nacimiento, muerte, la de lo inmigrantes y emigrantes
\[\begin{equation} \frac{\Delta N}{\Delta t} =\frac{\Delta B}{\Delta t} + \frac{\Delta I}{\Delta t} - \frac{\Delta D}{\Delta t} - \frac{\Delta E}{\Delta t}. \tag{3.1} \end{equation}\]
Para hacerlo más simple vamos a considerar que la tasa de inmigrantes y emigrantes es la misma \[ \frac{\Delta I}{\Delta t} - \frac{\Delta E}{\Delta t} = 0\]. Definiremos \[ \Delta t = h \], tal que \[ h \to 0\]. Entonces, la ecuación (3.1) puede escribirse como
\[\begin{equation} \frac{d N}{d t} =\frac{d B}{d t} - \frac{d D}{d t}. \tag{3.2} \end{equation}\]
Empecemos por considerar un escenario simple de como se comportara la tasa de nacimiento y muerte. Consideremos una hipótesis donde estas no dependen de la densidad en la población, \[ \frac{d B}{d t}=bN \] y \[ \frac{d D}{d t}=dN \] tal que
\[\begin{equation} \frac{d N}{d t} =(b-d)N. \tag{3.3} \end{equation}\]
Ahora tenemos una ley que describe el comportamiento en una población cuyo crecimiento no depende de su densidad. ¿Pero cual es el comportamiento que describe esta ley?
Una forma de averiguarlo es buscando la solución de la ecuación para luego analizarla. Entonces, ahora podemos integrar la ecuación diferencial para hallar la solución
\[\begin{align} \int_{0}^{t} d N \frac{1}{N} & = \int_{0}^{t} (b-d)dt, \\ Ln(N) - Ln(N(0)) & = (b-d)t-(b-d)0, \\ \frac{Ln(N)}{Ln(N(0))} & = (b-d)t-(b-d)0, \\ e^{\frac{Ln(N)}{Ln(N(0))}} & =e^{(b-d)t}, \\ N & = N(0)e^{(b-d)t}. \tag{3.4} \end{align}\] Recordemos que \[e^{Ln(x)}=x\].
Podemos analizar el comportamiento cualitativo de esta ley simple que gobierna el crecimiento de una población en la que la tasa de nacimiento y muerte no dependen de la densidad.
| Crecimiento exponencial |
| Así, definiendo \[\lambda = b - d.\] Si \[b > d,\] entonces \[\lambda > 0,\] por lo tanto la población crecerá de forma exponencial. Por el contrario, Si \[b < d,\] entonces \[\lambda < 0,\] por lo tanto la población decrece. Si \[b = d,\] la población se mantienen constate. |
Parece ser una formulación muy simplista. Pero, ¿con que porcentaje de error crees que un modelo tan simple como este puede explicar y anticipar el crecimiento de la población mundial?
Abre un nuevo script de R e implementemos unas lineas de código para evaluar nuestro modelo y responder a esta pregunta.
Empecemos por configurar los paquetes que utilizaremos
# 0. Instalar paquetes ####
if (!require('tidyverse'))
install.packages("tidyverse")
library(tidyverse)
if (!require('rio'))
install.packages("rio")
library(rio) Ahora vamos a importar los datos del crecimiento de la población mundial desde la plataforma de Our World in Data. Estos datos corresponden a la población de hecho en un país, zona o región al 1 de julio del año indicado —United Nations - Population Division (2022). Vamos a importar estos datos desde un google sheets utilizando la función import del paquete rio.
# 1. Importar datos ####
datos = import("https://docs.google.com/spreadsheets/d/1nMF-gz3aYIEud6Rk5qB9pqu2h8JGh93dUbLvO737uFM/edit#gid=151710516")
head(datos %>% subset(Entity == "World"))## Entity Code Year Population
## 37751 World OWID_WRL 1950 2499322000
## 37752 World OWID_WRL 1951 2543130400
## 37753 World OWID_WRL 1952 2590271000
## 37754 World OWID_WRL 1953 2640278800
## 37755 World OWID_WRL 1954 2691979300
## 37756 World OWID_WRL 1955 2746072000Ya que conocemos la solución de nuestra ley de crecimiento población, ajustemos los datos a esta ecuación. Antes de continuar veamos algunas igualdades auxilíales y útiles que se cumplen para la ecuación \[N=N(0)e^{\lambda t}\]. Esto es, conociendo \[\lambda\] para una población podemos conocer el tiempo que le ha llevado duplicar su tamaño población. Así, tomando \[2 N(0)=N(0) e^{\lambda t},\] tenemos que \[e^{\lambda t} = 2,\] aplicando una transformación de logaritmo natural tenemos que \[\lambda t^{*} = ln(2).\] Por lo tanto definiendo \[t^{*}:=T_{dupl}\] como el tiempo de duplicación tenemos que \[T_{dupl} = ln(2)/ \lambda.\] Note ademas que una forma sencilla de estimar el parámetro desconocido \[\lambda\] utilizando regresión lineal es aplicando una transformación de logaritmo a la eguación (3.4) tal que \[ln(N) = ln(N(0)) + \lambda t.\]
Ajustemos ahora nuestro modelo a los datos desde 1950 a 1980.
# 2. Ajuste ####
w.data = datos %>%
subset(Entity == "World") %>%
subset(Year < 1980)
lm.wp = lm(log(Population)~Year,w.data)
summary(lm.wp)##
## Call:
## lm(formula = log(Population) ~ Year, data = w.data)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.0070707 -0.0013752 0.0003501 0.0020352 0.0040674
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.651e+01 1.323e-01 -124.8 <2e-16 ***
## Year 1.956e-02 6.733e-05 290.5 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.003192 on 28 degrees of freedom
## Multiple R-squared: 0.9997, Adjusted R-squared: 0.9997
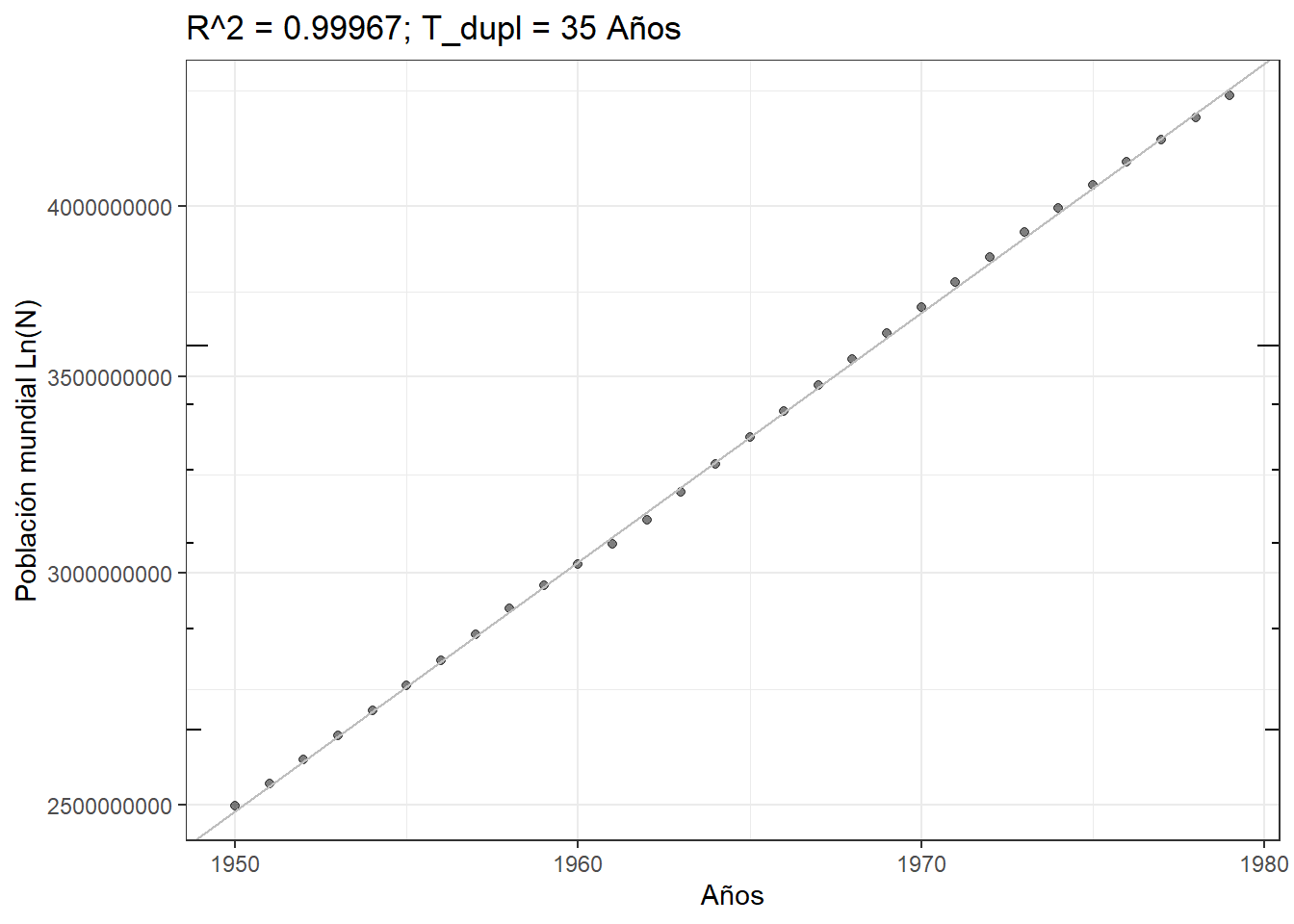
## F-statistic: 8.439e+04 on 1 and 28 DF, p-value: < 2.2e-16Observe que el modelo se ajusta bastante bien a los datos, \[R^{2} = 0.99967.\] Por lo tanto, —si bien consideramos que el comportamiento humano es bastante complejo, al igual que su historia de vida, con fases prereproductivas, reproductivas, y envejecidas—, un modelo tan simple como el de crecimiento exponencial es bastante bueno para describir el crecimiento de la población mundial en el intervalo de fecha que hemos analizados.
Ahora veamos el ajuste a conjunto de datos de entrenamiento y el tiempo de duplicación estimado para la población en este periodo:
t_dupl = signif(log(2) / summary(lm.wp)$coefficients[2],2)
# Función de transformación
scaleFUN <- function(x) sprintf("%.f", x)
w.data$Population = as.numeric(w.data$Population)
ggplot(w.data, aes(x = Year, y = Population)) +
geom_point(alpha = 0.5) +
scale_y_continuous(trans='log', labels=scaleFUN) +
theme_bw() + annotation_logticks(sides = "lr") +
geom_abline(
intercept = lm.wp$coefficients[1],
slope = lm.wp$coefficients[2],
colour = "gray"
) +
labs(
x = "Años",
y = "Población mundial Ln(N)",
title = paste0("R^2 = ",
signif(summary(lm.wp)$r.squared, 5),
"; T_dupl = ", signif(t_dupl, 2), " Años"
)
) 
Cuando ajustamos un modelo a un conjunto de datos estamos haciendo inferencia estadística. Mientras que la estadística descriptiva busca resumir la información de los datos, la inferencia estadística busca generalizaciones. Una forma de saber si nuestro modelo es una buena generalización es evaluando su rendimiento en un conjunto de prueba. Es decir, datos hacia el futuro que no hayan sido utilizados para el ajuste.
Veamos como le va a nuestro modelo de crecimiento de la población mundial anticipando el tamaño de la población una década hacia delante.
w.data2 = datos %>%
subset(Entity == "World") %>%
subset(Year > 1980)
obs_vs_esp = data.frame(Year = c(1981:1991)) %>%
mutate(Pop_esp = exp(lm.wp$coefficients[1] +
lm.wp$coefficients[2]*Year)) %>%
inner_join(.,w.data2, by = "Year") %>%
mutate(X2 = 100*(Pop_esp-Population)/Pop_esp) %>%
mutate(Años = c(1:11))
ggplot(obs_vs_esp, aes(x = Pop_esp, y = as.numeric(Population), color = X2, size = Años)) +
geom_point(alpha = 0.5) +
theme_bw() +
geom_abline(
intercept = 0,
slope = 1,
colour = "red"
) +
labs(
x = "Población esperada N",
y = "Población observada N"
) +
guides(color=guide_legend(title="% error"))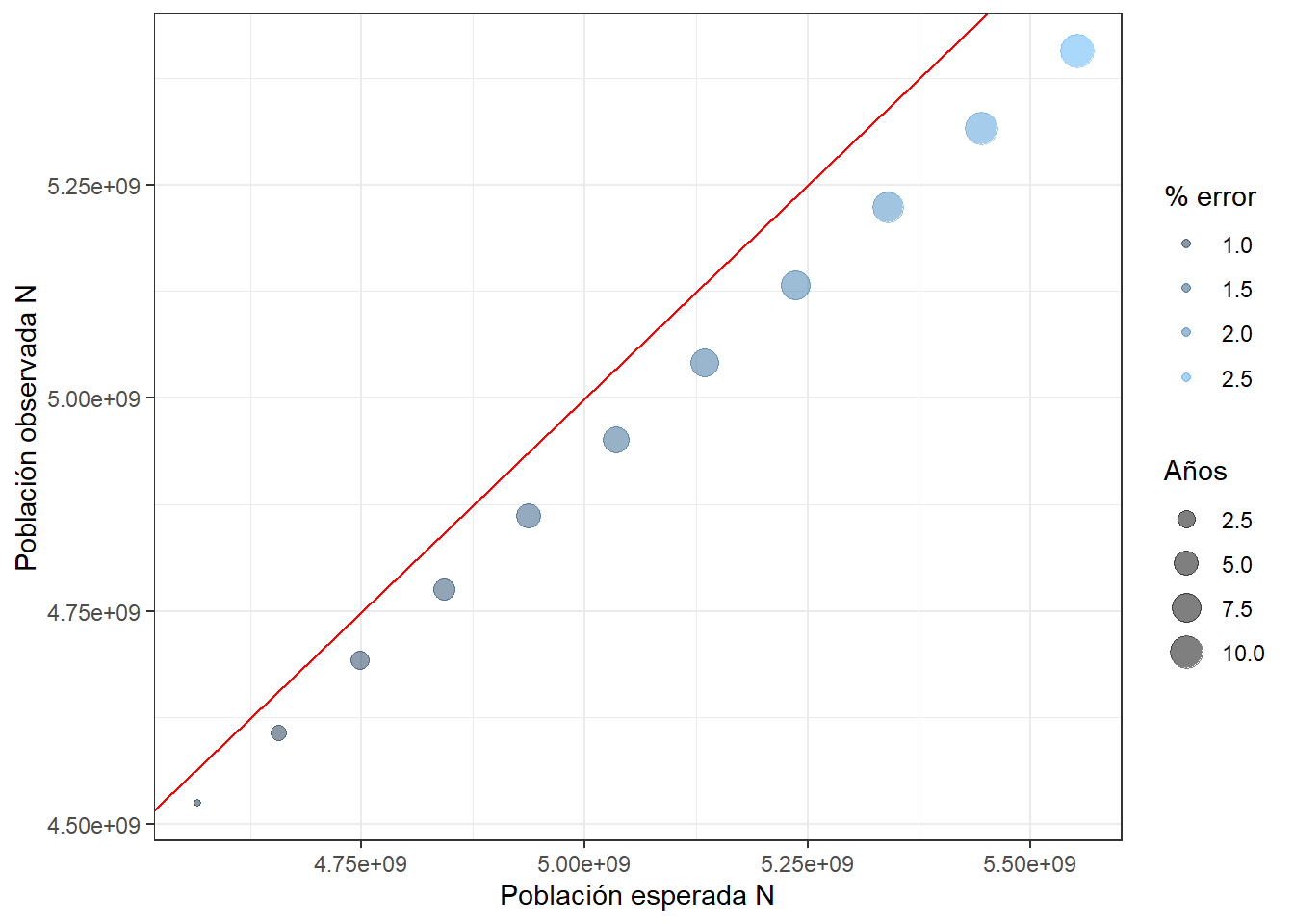
En la figura anterior se muestra una comparación entre lo esperado y lo observado. La linea roja representa un ajuste ideal tal que \[Observado=Esperado.\] La escala de colores en la figura corresponde al porcentaje de error definido como \[\begin{equation} \% error = 100\frac{Esp-Obs}{Esp}, \tag{3.5} \end{equation}\]. Mientras que el tamaño de los puntos representan los años de proyección. Note que el modelo sobreestima el tamaño observado y el porcentaje de error no es aleatorio en el tiempo, más bien tiende a aumentar hacia el futuro. Aún así el porcentaje de error en la proyección a un plazo de 10 años no es menor a un 3%. De hecho el % de error no es en promedio 0 como puedes ver a continuación.
summary(obs_vs_esp$X2)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.9126 1.2821 1.6962 1.7056 2.0811 2.6403En conclusión tenemos un modelo con un muy buen ajuste estadístico al conjunto de datos de entrenamiento y aún así al evaluarlo con datos de prueba muestra algunas limitaciones. Por lo tanto, podemos preguntarnos si ¿existe un mejor modelo para describir el crecimiento de la población mundial.
Consideremos ahora el caso de un modelo más general, el de crecimiento logístico. Tomando la ecuación (3.2), consideramos como hipótesis que tanto la tasa de nacimientos como la de mortalidad dependen de la densidad en la población \[\begin{align} \frac{dB}{dt} & = B(N), \\ \frac{dD}{dt} & = D(N). \tag{3.6} \end{align}\] Así, es de esperarse que la tasa de natalidad decrezca a medida que crece la densidad en la población (Lutz, Testa, and Penn 2006) y que la tasa de mortalidad aumente en la medida que aumenta la densidad de la población (Wang et al. 2013).
Formularemos esa hipótesis definiendo una función explicita para la tasa de mortalidad y tasa de natalidad \[\begin{align} B(N) & = b_{0} - k_{b}N, \\ D(N)& = d_{0} + k_{d}N. (\#eq:ddp) \end{align}\]
De allí que la ecuación (3.2) puede escribirse como \[\begin{align} \frac{d N}{d t} & = B(N) - D(N),\\ \frac{d N}{d t} & = [(b_{0} - k_{b}N)-(d_{0} + k_{d}N)]N. \tag{3.7} \end{align}\] Luego utilizando algunos cambios algebraicos podemos reescribir esta ecuación de una forma más comprensible.
| Equilibrio |
| Diremos que un sistema esta en equilibrio cuando su trayectoria permanece siempre constante en el tiempo. |
El equilibrio \[ N^{*} = cte. \] se cumple para (3.7), cuando \[ 0= [(b_{0} - k_{b}N^{*})-(d_{0} + k_{d}N^{*})]N^{*}.\] Esto ocurre si y solo si, \[ N=0 \] (equilibrio trivial) o \[\begin{equation} b_{0} - k_{b}N^{*} = d_{0} + k_{d}N^{*}, \tag{3.8} \end{equation}\] para \[ N^{*} > 0 \] (equilibrio no trivial). Así, la ecuación (3.8) puede escribirse en la forma \[\begin{align} b_{0} - d_{0} & = (k_{b} + k_{d})N^{*},\\ N^{*} & = \frac{b_{0} - d_{0}}{k_{b} + k_{d}} := K. \tag{3.9} \end{align}\] Donde K corresponde a un parámetro compuesto que describe la capacidad de carga bajo condiciones ambientales determinadas.
Ahora definiendo \[r:=b_{0}-d_{0}\] la ecuación (3.7) puede escribirse como \[ \frac{dN}{dt} = [(b_{0}-d_{0})-(k_{b}-k_{d})N]N. \] Luego, como la ecuación (3.9) satisface la igualdad \[ k_{b} + k_{d} = \frac{r}{K}. \] El sistema (3.7) puede escribirse como \[\begin{align} \frac{d N}{d t} & = \left(r - \frac{r}{K}N\right)N, \\ \frac{d N}{d t} & = rN\left(\frac{K-N}{K}\right); \tag{3.10} \end{align}\] en sus formas alternativas como \[\begin{equation} \frac{d N}{d t} = rN\left(1- \frac{N}{K}\right) \tag{3.11} \end{equation}\] o \[\begin{equation} \frac{d N}{d t} = rN - \frac{r}{K}N^{2}. \tag{3.12} \end{equation}\] Esta ultima —la cual deja ver polinomio de orden 2—, es conocida como ecuación de Bernulli. Así que para valores de \[ r, \frac{r}{K}> 0 \] esperaríamos que para \[ N \geq 0\] la tasa de cambio \[ \frac{d N}{d t} \] en la densidad de la población describa una parábola negativa con intercepto en cero. Esto a su vez nos permite anticipar de que el sistema satisface dos equilibrios \[ \frac{d N}{d t}=0 \], uno trivial cuando N=0 y otro no trivial _N*>0_ cuando la función de parábola negativa vuelve a pasar por \[ \frac{d N}{d t}=0.\] Puede ver en la ecuación (3.12) que eso ocurre si y solo si K=N.